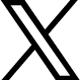ホーム > 研究 > 注目の研究 > 情報学 > ビッグデータに潜む"典型バイアス"に挑む
掲載日:2017.11.24
昨今のAI(人工知能)ブームで「ビッグデータ」ということばが世間を賑わせています。「ビッグデータ」は大量の数値の集まりです。たとえば、日本人の健診データは約1億人に対する検査値から成りますから、数十億の数値からなるビッグデータです。
このビッグデータは、病気の診断に活用できます。たとえば、糖尿病を診断するには、診断対象者と検査結果が最も類似する人(「近傍」)を検索して、その人が糖尿病であれば、診断対象者は糖尿病である、と診断します。
近傍検索によるビッグデータの活用は、一見、きめの細かい推論(個人の要望に応えた診断)を可能にするように思えます。しかし、そうでもないことが、最近分かってきました。というのは、診断結果を左右する「近傍」は、個々の診断対象者によって変化せず、ビッグデータのなかに少数存在する典型データに固定される傾向にあるのです(このため、診断結果は誰に対しても同じになりやすい)。私たちはこうした“典型バイアス”を解消することで、ビッグデータを個人の要望に応えられる形に変換する努力を進めています。
▲典型バイアスを解消することで、似ている事例がきれいに浮き上がる例
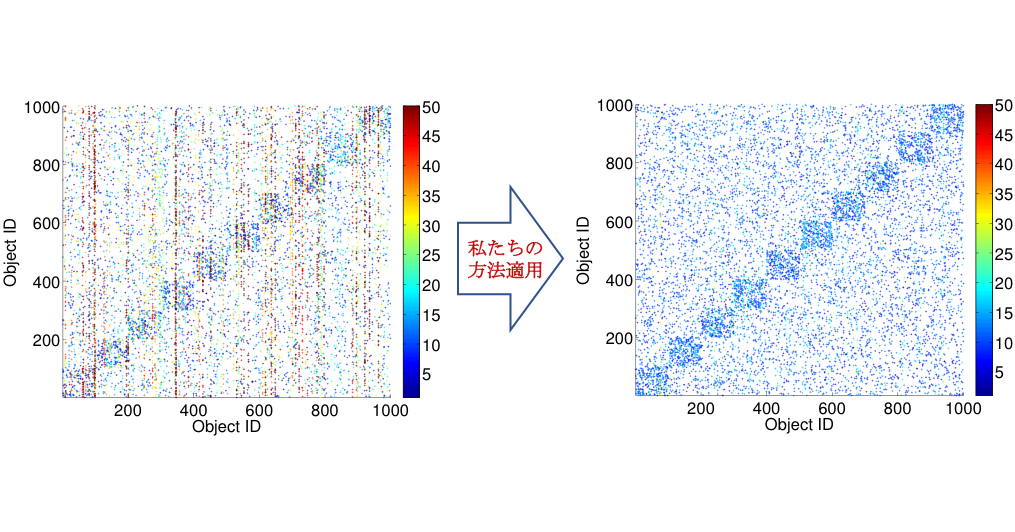
▲典型バイアス解消することで、曖昧になったクラスタ構造を復活させる例